Benčmark test: GLM-4.6, GLM-4.5, DeepSeek-V3.2-Exp, Claude Sonnet 4 i Claude Sonnet 4.5
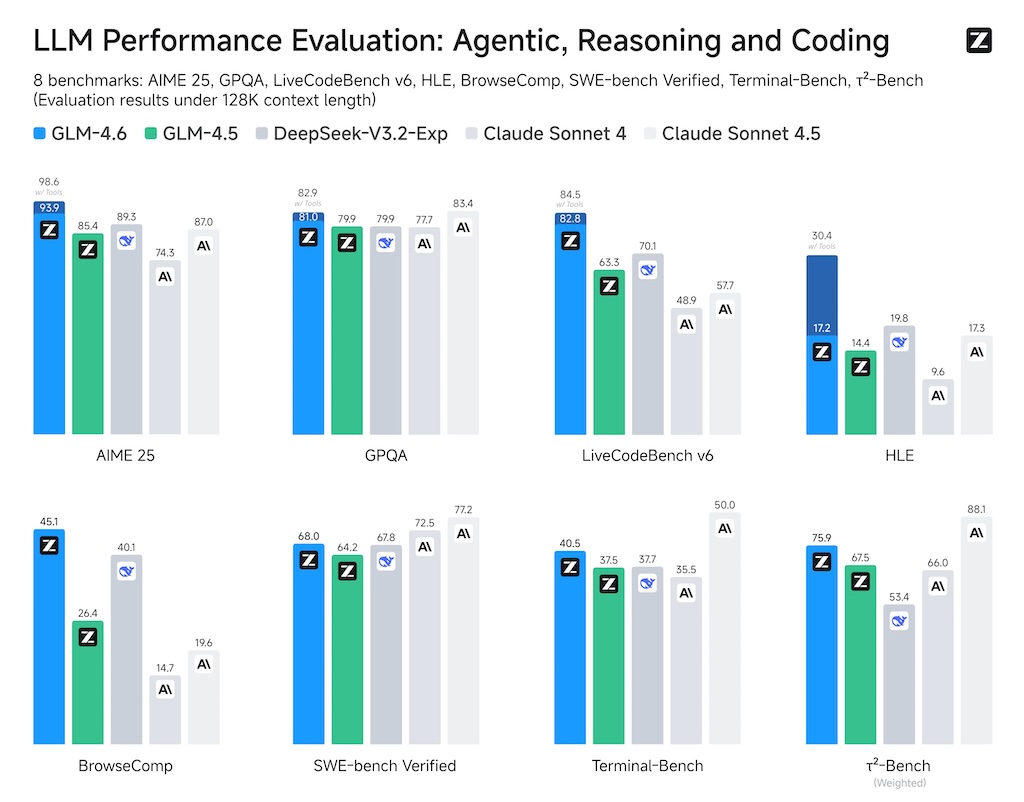
Evaluacija performansi LLM-a: Agentsko razmišljanje, zaključivanje i kodiranje
8 uporednih testova: AIME 25, GPQA, LiveCodeBench v6, HLE, BrowseComp, SWE-bench Verified, Terminal-Bench, τ²-Bench (rezultati evaluacije ispod 128K dužine konteksta)
LLM modeli testirani: GLM-4.6
GLM-4.5
DeepSeek-V3.2-Exp
Claude Sonnet 4
Claude Sonnet 4.5
Reperne (banchmark) testove treba uzimati sa rezervom.
8 uporednih testova: AIME 25, GPQA, LiveCodeBench v6, HLE, BrowseComp, SWE-bench Verified, Terminal-Bench, τ²-Bench (rezultati evaluacije ispod 128K dužine konteksta)
LLM modeli testirani: GLM-4.6
GLM-4.5
DeepSeek-V3.2-Exp
Claude Sonnet 4
Claude Sonnet 4.5
Reperne (banchmark) testove treba uzimati sa rezervom.

Komentari
Nema komentara. Šta vi mislite o ovome?