Cena slobode: Šta nam testovi govore o necenzurisanim Qwen i Gemma modelima?
U potrazi za "svetim gralom" lokalnih jezičkih modela (LLM), korisnici često teže potpunoj autonomiji: modelu koji je oslobođen korporativnih zaštitnih ograda, ali koji zadržava kognitivnu oštrinu svog baznog izvornika. Međutim, u zajednici entuzijasta tinja opravdan strah – da li procesi poput "abliteracije" (uklanjanja odbijanja) zapravo vrše lobotomiju nad inteligencijom modela? Da li je moguće otključati potisnuto znanje bez kolapsa logičke strukture?
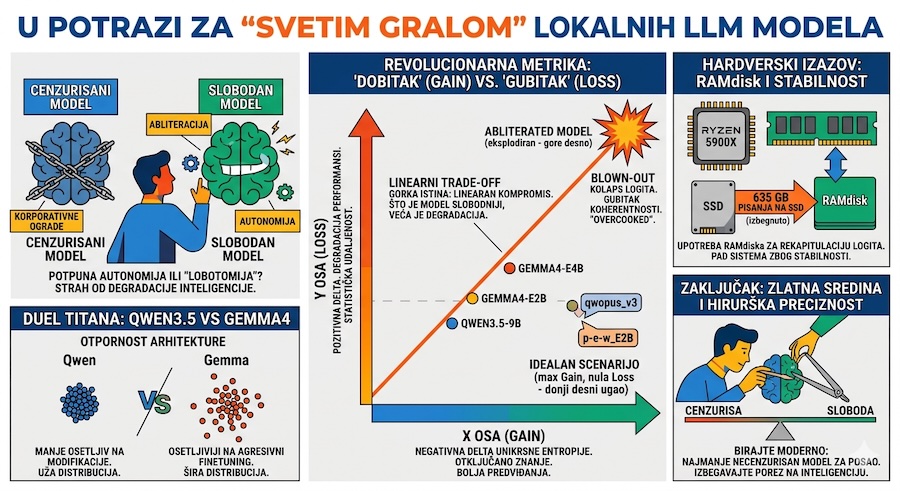
Revolucionarna Metrika: Razdvajanje "Dobitka" i "Gubitka" kroz logite
Nedavna istraživanja korisnika Tryshea sa r/LocalLLaMA zajednice donose nam preko potreban metodološki pomak. Umesto oslanjanja na generički skor perpleksnosti (PPL), koji nam daje samo mutnu, prosečnu sliku neizvesnosti, Tryshea je primenio inovativan pristup: 2D scatter plot razlika unakrsne entropije.
Ključ je u analizi predznačnih delti po tokenu (per-token signed deltas) duž sekvence. Kako standardni alati poput llama-perplexity.exe ne daju ove podatke direktno, autor je morao da primeni "sirovu silu" – pozivajući --save-all-logits dva puta i parsirajući gigantske logit fajlove putem NumPy-ja. Ovaj proces omogućava razdvajanje performansi na dve ose:
- X osa (Gain): Negativna delta unakrsne entropije. Ovde model predviđa tekst bolje (sa većom log-verovatnoćom) nego bazni model. U idealnom scenariju, visok Gain na necenzurisanom datasetu znači da je model uspešno "otključao" znanje koje je baza potiskivala.
- Y osa (Loss): Pozitivna delta. Ovo je direktna mera degradacije. Što je vrednost na Y osi veća, to su predviđanja modela statistički udaljenija od logike baze, što ukazuje na to da je finetuning narušio originalnu probabilističku distribuciju.
Savršen necenzurisan model bi se nalazio u donjem desnom uglu: maksimalan Gain (sloboda) uz nula Loss-a (inteligencija). Nažalost, podaci pokazuju da takav model trenutno ne postoji.
Gorka istina: "Trade-off" je linearan
Analiza modela na specifičnom datasetu – koji je autor opisao kao "dubiozan" (mešavina koda, multilingualnih tekstova, 4chan postova i "anarchy cookbook" priručnika) – otkrila je surovu realnost: "besplatan ručak" u svetu LLM-ova je iluzija.
"Čini se da je trenutna tehnologija necenzurisanja loša u očuvanju predviđanja baznog modela dok mu samo dodaje bolja predviđanja. Više se radi o linearnom kompromisu (trade-off) kroz modele: što je model više necenzurisan, to uzrokuje veću degradaciju."
Dok se KL-divergencija (KLD) obično koristi za poređenje različitih nivoa kvantizacije (poput Q8_0 naspram Q4_K_M), ovde PPL delta jasno pokazuje da svaki procenat dodatne "slobode" deluje kao direktan porez na preciznost originalnih logita.
Duel titana: Arhitektura Qwen3.5 protiv Gemme4
Testiranje je obuhvatilo specifične iteracije kao što su Qwen3.5-4B, Qwen3.5-9B, kao i Gemma4-E2B i E4B. Rezultati su ukazali na fascinantne razlike u arhitektonskoj otpornosti:
- Qwen3.5 (4B i 9B): Ovi modeli su se pokazali kao znatno "otporniji" na modifikacije. Qwen arhitektura dozvoljava drastičnije uklanjanje odbijanja bez rasipanja logičke strukture. Model
qwopus_v3se posebno istakao, pokazujući najužu distribuciju rezultata i visok afinitet prema testnom datasetu. - Gemma4: Verzije poput
p-e-w_E2Bsu pokazale solidne rezultate, ali je porodica Gemma4 generalno podložnija "eksploziji" (blown-out) na grafikonu. Čak i kod naprednijih E4B iteracija, modifikacije su često dovodile do značajnog udaljavanja od baze, što sugeriše da su ovi modeli osetljiviji na agresivni finetuning.
Fenomen "Eksplodiranih" (Blown-out) modela
Posebno upozorenje zaslužuju takozvani "abliterated" modeli koji na grafikonima izgledaju potpuno haotično. U ovim slučajevima ne govorimo o suptilnom otključavanju znanja, već o kolapsu logita.
Kada model postane "blown-out", njegova Y osa (Loss) raste do ekstrema. To znači da model pravi drastično drugačije izbore tokena koji su statistički neopravdani. Iako ovakvi modeli više ne odbijaju nijedan upit, oni to čine po cenu koherentnosti. Oni nisu postali "slobodniji" u intelektualnom smislu; oni su jednostavno postali nepredvidljivi i "overcooked" (prekuvani) tokom treninga, gubeći finu kalibraciju koju je postavio originalni tim.
Hardverski pakao: 635 GB pisanja na disk
Ovaj eksperiment nije bio samo intelektualni, već i hardverski izazov. Autor je tokom 9.730 evaluacija (koje su trajale preko 30 sati) suočio svoj Ryzen 5900X sa ozbiljnim problemima stabilnosti. Sistem se rušio pet puta, što je na kraju rešeno isključivanjem Cool'n'Quiet i C-states funkcija, uz manuelni downclock memorije na 3200MHz.
Još impresivniji je podatak o radu sa podacima: kako bi izbegao neverovatnih 635 GB pisanja na SSD tokom rekapitulacije logita, autor je koristio RAMdisk. Ovo je podsetnik da rigorozna AI evaluacija na lokalnom nivou zahteva ne samo softversku domišljatost, već i hardver spreman da radi na ivici silicijumskog izdržaja.
Zaključak: Hirurška preciznost umesto anarhije
Budućnost lokalnih LLM-ova neće zavisiti od toga ko može najviše da "razbije" cenzuru, već ko to može uraditi sa najmanjom štetom po osnovnu inteligenciju. Podaci Tryshea-e nam govore da je kriva degradacije neumoljiva.
Kao korisnici, moramo prestati da jurimo modele sa "nula odbijanja" po svaku cenu. Umesto toga, birajte hirurški precizno: tražite najmanje necenzurisan model koji završava vaš specifičan posao. Svaki procenat slobode koji zapravo ne koristite je direktan porez na inteligenciju i logiku vašeg modela. Da li smo spremni da žrtvujemo 10% logike za 100% slobode, ili ćemo nastaviti da tražimo onu zlatnu sredinu gde model ostaje pametan, ali prestaje da morališe? Dok je ne nađemo, birajte svoje kvante i finetune-ove mudro.
Izvor: reddit.com

Komentari
Nema komentara. Šta vi mislite o ovome?