Pregled arhitektura velikih jezičkih modela (LLM) u 2025. godini
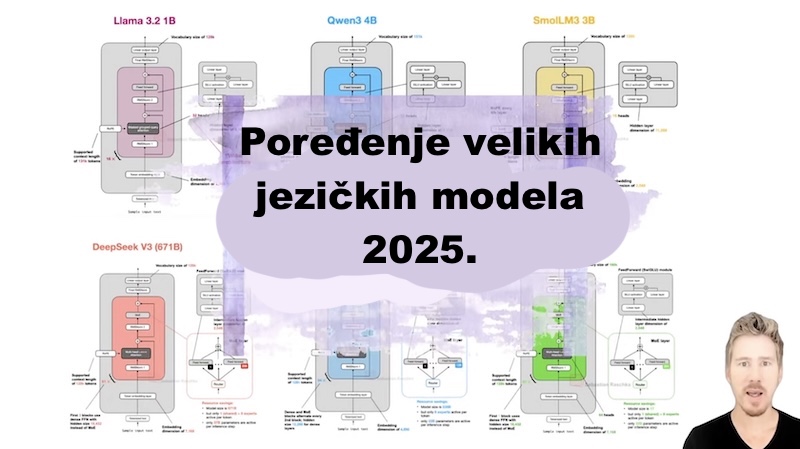
Analiza ključnih jezičkih modela objavljenih 2024. i 2025. godine otkriva da, iako fundamentalna Transformer arhitektura ostaje osnova, došlo je do značajne evolucije u ključnim komponentama. Tri dominantna trenda definišu trenutno stanje razvoja: 1. uspon Mixture-of-Experts (MoE) arhitektura, 2. potraga za efikasnijim mehanizmima pažnje i 3. oživljavanje linearne pažnje za obradu ekstremno dugih konteksta.
MoE je postao standardna strategija za skaliranje modela na stotine milijardi, pa čak i biliona (triliona po američkom brojnm sistemu) parametara, a da se pritom zadrži efikasnost pri zaključivanju (inference). Modeli kao što su DeepSeek-V3, Llama 4 i Kimi K2 koriste ovaj pristup kako bi povećali kapacitet modela (sposobnost usvajanja znanja) bez proporcionalnog povećanja računarskih troškova po generisanom tokenu. Ključne varijacije unutar MoE dizajna uključuju upotrebu "zajedničkog eksperta" (shared expert), odnos između broja i veličine eksperata, kao i nivo "retkosti" (sparsity) modela.
Paralelno, evolucija mehanizama pažnje se udaljila od standardne Multi-Head Attention (MHA). Grouped-Query Attention (GQA) je postala industrijski standard kao efikasnija zamena, dok modeli poput DeepSeek-V3 i Kimi K2 uvode Multi-Head Latent Attention (MLA), koja kompresuje tenzore ključeva i vrednosti radi uštede memorije. Gemma 3 i GPT-OSS koriste Sliding Window Attention kako bi ograničili pažnju na lokalni kontekst i smanjili memorijske zahteve KV keša.
Najnoviji trend je oživljavanje linearne pažnje, koja rešava problem kvadratne složenosti tradicionalne pažnje. Modeli kao što su Qwen3-Next i Kimi Linear koriste hibridne pristupe, kombinujući linearne blokove (npr. Gated DeltaNet) sa slojevima pune pažnje. Ovaj pristup omogućava obradu konteksta od preko 250.000 tokena, otvarajući nove mogućnosti za modele, iako se još uvek balansiraju performanse i računarska efikasnost. Ostale značajne inovacije uključuju napredne strategije normalizacije (npr. QK-Norm) za poboljšanje stabilnosti treninga i eksperimente sa pozicionim kodiranjem, kao što su No Positional Embeddings (NoPE) i Partial RoPE.
Ključni arhitektonski trendovi i inovacije
Uspon Mixture-of-Experts (MoE) arhitektura
MoE arhitekture predstavljaju ključnu promenu u dizajnu velikih jezičkih modela. Umesto da svaki token prolazi kroz isti, gusti (dense) FeedForward sloj unutar Transformer bloka, MoE pristup koristi više paralelnih "ekspertskih" slojeva (koji su i sami FeedForward mreže). Ruter dinamički bira mali podskup ovih eksperata za obradu svakog pojedinačnog tokena.
- Glavna prednost: Ovaj pristup omogućava drastično povećanje ukupnog broja parametara modela, što povećava njegov kapacitet za učenje i skladištenje znanja, dok broj aktivnih parametara koji se koriste tokom zaključivanja ostaje relativno mali. Na primer, DeepSeek-V3 ima 671 milijardu ukupnih parametara, ali tokom zaključivanja koristi samo 37 milijardi.
- Modeli koji koriste MoE: DeepSeek-V3, Llama 4, Qwen3 (MoE varijante), Kimi K2, GPT-OSS, Grok 2.5, GLM-4.5.
Ključne dizajnerske odluke u MoE
| Dizajnerska odluka | Opis | Primeri modela |
| Zajednički Ekspert (Shared Expert) | Jedan ekspert koji je uvek aktivan za svaki token. Smatra se da uči zajedničke, ponavljajuće obrasce, oslobađajući druge eksperte da se specijalizuju. | DeepSeek-V3, Grok 2.5, GLM-4.5, Qwen3-Next |
| Broj naspram Veličine Eksperata | Trend ide ka korišćenju većeg broja manjih eksperata, jer se pokazalo da to poboljšava performanse. Međutim, neki modeli i dalje koriste manji broj većih eksperata. | Više manjih: DeepSeek-V3 (256), Qwen3-Next (512). Manje većih: Llama 4, gpt-oss (32), Grok 2.5 (8). |
| Retkost (Sparsity) | Odnos aktivnih parametara prema ukupnom broju. Veća retkost znači manji računarski otisak po tokenu, ali zahteva pažljivo balansiranje kako bi se očuvale performanse. | MiniMax-M2 (4.37% aktivnih) je "ređi" od Qwen3 235B (9.36% aktivnih). |
Evolucija mehanizama pažnje
Iako je skalirana dot-product pažnja i dalje srž, njene implementacije su se značajno diversifikovale radi poboljšanja efikasnosti.
- Grouped-Query Attention (GQA): Postala je novi standard, zamenivši Multi-Head Attention (MHA). GQA smanjuje memorijski protok i veličinu KV keša tako što više "query" glava deli iste projekcije ključeva (K) i vrednosti (V). Koriste je Llama 4, Qwen3, Mistral 3.1 i GPT-OSS.
- Multi-Head Latent Attention (MLA): Alternativa GQA koju koristi DeepSeek. MLA kompresuje K i V tenzore u prostor niže dimenzije pre skladištenja u KV keš. Studije u DeepSeek-V2 radu sugerišu da MLA nudi bolje performanse modeliranja u poređenju sa GQA. Koriste je DeepSeek-V3 i Kimi K2.
- Sliding Window Attention: "Lokalni" mehanizam pažnje gde svaki token može da prisustvuje samo ograničenom prozoru susednih tokena. Ovo značajno smanjuje memorijske zahteve KV keša za duge sekvence. Gemma 3 koristi hibridni pristup sa odnosom 5:1 između slojeva sa kliznim prozorom i slojeva sa punom (globalnom) pažnjom. GPT-OSS takođe koristi ovaj mehanizam.
Oživljavanje linearne pažnje
Tradicionalna pažnja ima računarsku i memorijsku složenost od O(n²), gde je n dužina sekvence, što je čini neefikasnom za veoma duge kontekste. Linearna pažnja, sa složenošću O(n), dugo je bila teorijska alternativa, ali sa kompromisima u pogledu tačnosti. U 2025. godini, hibridni modeli su je ponovo učinili relevantnom.
- Hibridni pristup: Modeli kao što su Qwen3-Next i Kimi Linear ne zamenjuju u potpunosti tradicionalnu pažnju. Umesto toga, koriste mešavinu slojeva: većina Transformer blokova koristi efikasnu linearnu varijantu, dok manjina koristi punu pažnju kako bi se zadržala preciznost. Tipičan odnos je 3:1.
- Gated DeltaNet: Ključna komponenta u ovim hibridima. To je varijanta linearne pažnje inspirisana rekurentnim neuronskim mrežama, koja koristi "delta pravilo" i mehanizme gejtinga za ažuriranje stanja, čime se efikasno obrađuju duge zavisnosti.
- Kimi Delta Attention (KDA): Poboljšanje Gated DeltaNet mehanizma korišćeno u Kimi Linear. Umesto skalarnog gejta, KDA koristi gejting po kanalima, što omogućava finiju kontrolu nad memorijom i poboljšava rezonovanje u dugim kontekstima.
Strategije normalizacije i stabilnost treninga
Pravilna normalizacija je ključna za stabilan trening dubokih Transformer modela.
- Pozicioniranje Normalizacionih Slojeva:
- Pre-Norm: Standardni pristup (popularizovan od strane GPT-2) gde se normalizacioni sloj (obično RMSNorm) postavlja pre modula pažnje i FeedForward sloja. Poboljšava stabilnost gradijenata.
- Post-Norm: Originalni pristup iz "Attention is all you need" papira. OLMo 2 koristi modifikovanu verziju Post-Norm-a (unutar rezidualne veze) koja dodatno poboljšava stabilnost treninga.
- Hibridna Normalizacija: Gemma 3 koristi RMSNorm slojeve i pre i posle modula pažnje, kombinujući prednosti oba pristupa.
- QK-Norm: Dodatni RMSNorm sloj koji se primenjuje direktno na tenzore upita (Q) i ključeva (K) unutar mehanizma pažnje, pre primene RoPE. Pomaže u stabilizaciji treninga. Koriste ga OLMo 2 i Gemma 3.
- Per-Layer QK-Norm: Inovacija u MiniMax-M2, gde se ne koristi samo jedan QK-Norm po sloju, već jedinstveni QK-Norm za svaku pojedinačnu glavu pažnje.
Inovacije u pozicionom kodiranju
- Rotary Positional Embeddings (RoPE): I dalje je de facto standard za unošenje pozicionih informacija rotiranjem vektora Q i K.
- No Positional Embeddings (NoPE): Eksperimentalni pristup gde se eksplicitne pozicione informacije u potpunosti izostavljaju. Model uči pozicije implicitno iz kauzalne maske pažnje. Studije sugerišu da ovo može poboljšati generalizaciju na dužim sekvencama. SmolLM3 ga koristi u nekim slojevima, a Kimi Linear u svojim MLA slojevima.
- Partial RoPE: Pristup koji koristi MiniMax-M2, gde se RoPE primenjuje samo na deo dimenzija svake glave pažnje. Smatra se da ovo sprečava "prekomernu" rotaciju u dugim sekvencama i poboljšava ekstrapolaciju.
Analiza ključnih modela
| Model/Familija | Arhitektura | Ključne karakteristike |
| DeepSeek V3 / Kimi K2 | MoE sa MLA | DeepSeek-V3 (671B/37B): uveo MLA kao efikasniju alternativu GQA; koristi MoE sa velikim brojem (256) malih eksperata i zajedničkim ekspertom. Kimi K2 (1T): skalirana verzija DeepSeek-V3 arhitekture sa još više eksperata, postižući vrhunske performanse. |
| Qwen3 / Qwen3-Next | MoE sa GQA / Hibrid | Qwen3 (Dense): Dublji i uži od konkurenata poput Llama 3. Qwen3 (MoE): Sličan DeepSeek-V3, ali bez zajedničkog eksperta. Qwen3-Next: Fokusiran na efikasnost; uvodi Gated DeltaNet hibridnu pažnju za 262k kontekst, vraća zajedničkog eksperta i koristi Multi-Token Prediction (MTP). |
| Gemma 3 | Dense sa GQA | Koristi Sliding Window Attention (odnos 5:1 lokalne prema globalnoj) za smanjenje memorije KV keša. Jedinstvena normalizacija sa RMSNorm slojevima i pre i posle modula pažnje. |
| Llama 4 | MoE sa GQA | Metin ulazak u MoE prostor. Koristi manji broj većih eksperata u poređenju sa DeepSeek-om i naizmenično postavlja MoE i guste (dense) Transformer blokove. Koristi standardni GQA. |
| GPT-OSS | MoE sa GQA | Prvi open-weight model OpenAI-a od GPT-2. "Široka", a ne "duboka" MoE arhitektura sa malim brojem (32) velikih eksperata. Koristi Sliding Window Attention, vraća "bias" jedinice u slojevima pažnje i uvodi naučene "attention sinks" za stabilnost. |
| MiniMax-M2 | MoE sa GQA | Trenutno jedan od najboljih modela po benčmarcima. Vratio se na punu pažnju nakon eksperimenta sa linearnom pažnjom u M1. Arhitektonski sličan Qwen3, ali "ređi" (manji procenat aktivnih parametara). Uvodi Per-Layer QK-Norm i Partial RoPE. |
| Kimi Linear | Hibridna Pažnja | Vodeći model sa linearnom pažnjom. Koristi hibridni 3:1 odnos između Kimi Delta Attention (KDA) blokova i punih MLA blokova. Dizajniran za superiorne performanse i efikasnost na ekstremno dugim kontekstima. |
| OLMo 2 / SmolLM3 | Dense sa MHA / GQA | OLMo 2: Značajan zbog transparentnosti. Uvodi jedinstvenu Post-Norm šemu i QK-Norm za stabilnost treninga. SmolLM3: Koristi NoPE (bez pozicionih embedinga) u svakom četvrtom sloju radi bolje generalizacije na duge sekvence. |
| GLM-4.5 / Grok 2.5 | MoE sa GQA | GLM-4.5: Poput DeepSeek-V3, počinje sa nekoliko gustih slojeva radi stabilnosti pre uvođenja MoE blokova; koristi zajedničkog eksperta. Grok 2.5: Uvid u produkcioni sistem; MoE arhitektura koja odražava stariji trend manjeg broja velikih eksperata; sadrži modul koji funkcioniše kao zajednički ekspert. |
Kompletan izveštaj nalazi se OVDE
Tagovi: #modeli #LLM

Komentari
Nema komentara. Šta vi mislite o ovome?