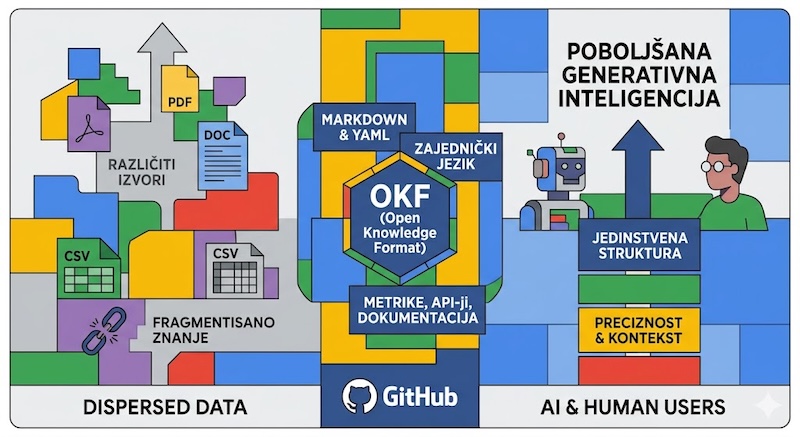
Google Cloud je predstavio Open Knowledge Format (OKF), novi otvoreni standard dizajniran da premosti jaz u razmeni informacija između veštačke inteligencije i ljudskih korisnika. Ovaj format omogućava organizacijama da pretvore rasute podatke iz različitih izvora u jedinstvenu strukturu koju AI agenti mogu lako razumeti i koristiti za preciznije obavljanje zadataka. Umesto nove platforme, OKF nudi zajednički jezik zasnovan na Markdown i YAML datotekama, što ga čini pristupačnim i za softverske inženjere i za automatizovane sisteme. Standardizacijom koncepata poput metrika, API-ja i tehničke dokumentacije, Google teži da spreči fragmentaciju znanja unutar preduzeća. Trenutno dostupna na GitHub-u, ova inicijativa podstiče zajednicu da doprinese razvoju ekosistema koji će pob...